I've recently been experimenting with running a Livepeer orchestrator / transcoder on my newly acquired rtx 3080. I also do ethereum mining on it along with some old spare AMD rx 580 GPUs when I'm not using it for playing games.
I've got three separate computers at my apartment, my main gaming rig, an older gaming rig, and a server which is mostly used for plex (and at one time to play with chia mining).
**First attempt: orch + transcoder on same device**
My first attempt was to run both the transcoder and orchestrator on the same device (my main gaming rig). My main gaming rig is a dual boot Ubuntu 20.04 / Windows 11 setup. It's got my RTX 3080, 64 GB of RAM, and an AMD Ryzen 5900X CPU.
I tried putting an ethereum full-node on my server computer (running Ubunut 20.04, an Intel core i5-7500, 32 GB of RAM, and an AMD RX 580) so that it could stay in sync while I played video games, but it was having trouble keeping up. I thought this was because it's located in my laundry room and it was connected via a crappy powerline networking adapter. I couldn't really run ethernet wiring to it, so I bought a 3000Mbps Wi-Fi adapter [https://www.amazon.com/dp/B086V3KS9F?psc=1&ref=ppx_yo2_dt_b_product_details](https://www.amazon.com/dp/B086V3KS9F?psc=1&ref=ppx_yo2_dt_b_product_details). Turned out it was the storage that was too slow to keep up. I could get an SSD, but I was too lazy to do the re-install. So I ran the full-node on the main gaming rig as well since that had some fast NVMEs in it.
This worked pretty well, I was able to get within the top 20 or so on the performance scores, but I wanted things to keep working if I started playing video games (and in the case where I might buy some more nvidia cards to stick in the other computers) so I wanted to move the orchestrator to the cloud.
**Second attempt: orch on Digital Ocean, transcoder on gaming rig**
I thought that I might be able to fall back to CPU mining on a couple of my spare machines since the AMD cards currently can't be used (AFAIK) for livepeer transcoding. I got this all hooked together so that the orchestrator was on Digital Ocean, my main gaming rig a GPU transcoder, and my backup desktop, and server were both setup to be CPU transcoders. I used Digital Ocean because I already have this website hosted on there. This worked, but the performance was terrible, often gettings scores of 3/10. So I abandoned this approach and just stuck to the GPU transcoder with the orchestrator on my main gaming rig. However, I still wasn't able to achieve the high scores I was getting with gaming rig doing both jobs together. I was curious if it was because digital ocean was slow. I converted the droplet instance to a larger machine to see if that helped. It did not (I was running in the SFO-2 zone).
Ansible tasks for running a livepeer orchestrator as a docker container. Note the eth wallet file, the `orchSecret` and the `ethPassword` are stored encrypted using ansible vault.
```
- name: Create Livepeer Directories
tags: livepeer
file:
mode: '0700'
path: /home/jason/.lpData/mainnet/keystore
state: directory
- name: Copy Ethereum Wallet to Livepeer
tags: livepeer
copy:
src: files/UTC--2016-03-12T21-58-48.509345400Z--74ba897f65f04008d8eff364efcc54b0a20e17eb
dest: /home/jason/.lpData/mainnet/keystore/UTC--2016-03-12T21-58-48.509345400Z--74ba897f65f04008d8eff364efcc54b0a20e17eb
mode: '0600'
# note: can't run as both transcoder and orchestrator at same time
# if you want to use orch secret and allow other transcoders to register
# also note: if the price per pixel > 1200 the perf test won't run
- name: Deploy Livepeer Orchestrator
tags: livepeer
vars:
ansible_python_interpreter: "/usr/bin/env python3-docker"
community.docker.docker_container:
name: livepeer
image: livepeer/go-livepeer:master
pull: true
restart_policy: unless-stopped
command: >
-network mainnet -ethUrl http://localhost:8545 -ethAcctAddr 0x74ba897f65f04008d8eff364efcc54b0a20e17eb -orchestrator -pricePerUnit 995
-pixelsPerUnit 1 -autoAdjustPrice=false -serviceAddr lp.jasonernst.com:8935 -reward=false -orchSecret {{ orchSecret }}
-ethPassword {{ ethPassword }} -monitor -cliAddr 0.0.0.0:7935
volumes:
- "/home/jason/.lpData:/root/.lpData"
network_mode: host
```
Ansible tasks for running the GPU transcoder in a docker container:
```
# note: this requires the host to have the nvenv nvidia patch if it is a consumer
# nvidia card: https://github.com/keylase/nvidia-patch
- name: Deploy Livepeer Transcoder with Nvidia GPU
tags: livepeer
vars:
ansible_python_interpreter: "/usr/bin/env python3-docker"
community.docker.docker_container:
name: livepeer
image: livepeer/go-livepeer:master
pull: true
restart_policy: unless-stopped
device_requests:
- driver: nvidia
count: -1
capabilities:
- gpu
command: >
-transcoder -network mainnet -ethUrl http://ubuntu-desktop-beast:8545 -nvidia 0 -orchSecret {{ orchSecret }}
-orchAddr lp.jasonernst.com:8935 -monitor --cliAddr 0.0.0.0:7935 -reward=false -ethAcctAddr 0x74ba897f65f04008d8eff364efcc54b0a20e17eb
-ethPassword {{ ethPassword }}
network_mode: host
volumes:
- "/home/jason/.lpData:/root/.lpData"
```
So I tried using this tool: [https://cloudpingtest.com/](https://cloudpingtest.com/) to compare the different providers to see which might have the lowest round trip times, since that was the part of the score that I was doing poorly on. I paid particular attention to the the zones which the performance tests for Livepeer are run from: [https://leaderboard-serverless.vercel.app/api/raw_stats?orchestrator=0x74ba897f65f04008d8eff364efcc54b0a20e17eb](https://leaderboard-serverless.vercel.app/api/raw_stats?orchestrator=0x74ba897f65f04008d8eff364efcc54b0a20e17eb).
I also explored putting the ethereum full-node directly on the orchestrator on digital ocean, but this would have been quite expensive since it requires > 500GB of storage, so I abandoned that. I also experimented with using infura, but it would occasionally give errors, and I was getting warnings of reaching the free tier caps, so I stuck with my own eth node running at my house.
**Third attempt: orch on AWS: us-west-1, transcoder on gaming rig**
This time I managed to get fast results (note the success rate is only 33% because it's only ran 1/3 tests since it's come online again, but the latency score is the highest on the board for LA and 6th globally):

Global Score by Latency
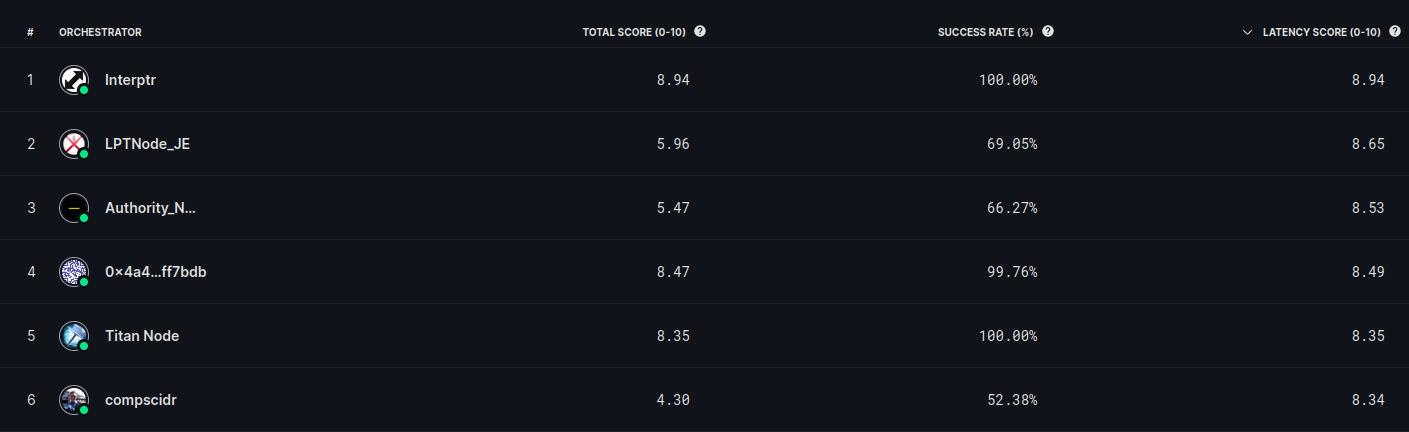
So, it sees now the biggest bottleneck is my crappy non-symmetric Xfinity internet. It has ~1Gbps down, but only 35-40Mbps up. I've currently capped my streams at 10 because much higher than that and it seems to saturate the connection, but its been a fun exercise in figuring out how to set everything up.
This is the terraform config I used to deploy the ec2 instance, and point `lp.jasonernst.com` to it.
```
resource "aws_instance" "lp-jasonernst-com" {
ami = "ami-053ac55bdcfe96e85"
instance_type = "t2.micro"
key_name = aws_key_pair.aws_devops.key_name
}
resource "digitalocean_record" "CNAME-lp" {
domain = digitalocean_domain.default.name
type = "A"
name = "lp"
value = aws_instance.lp-jasonernst-com.public_ip
}
```
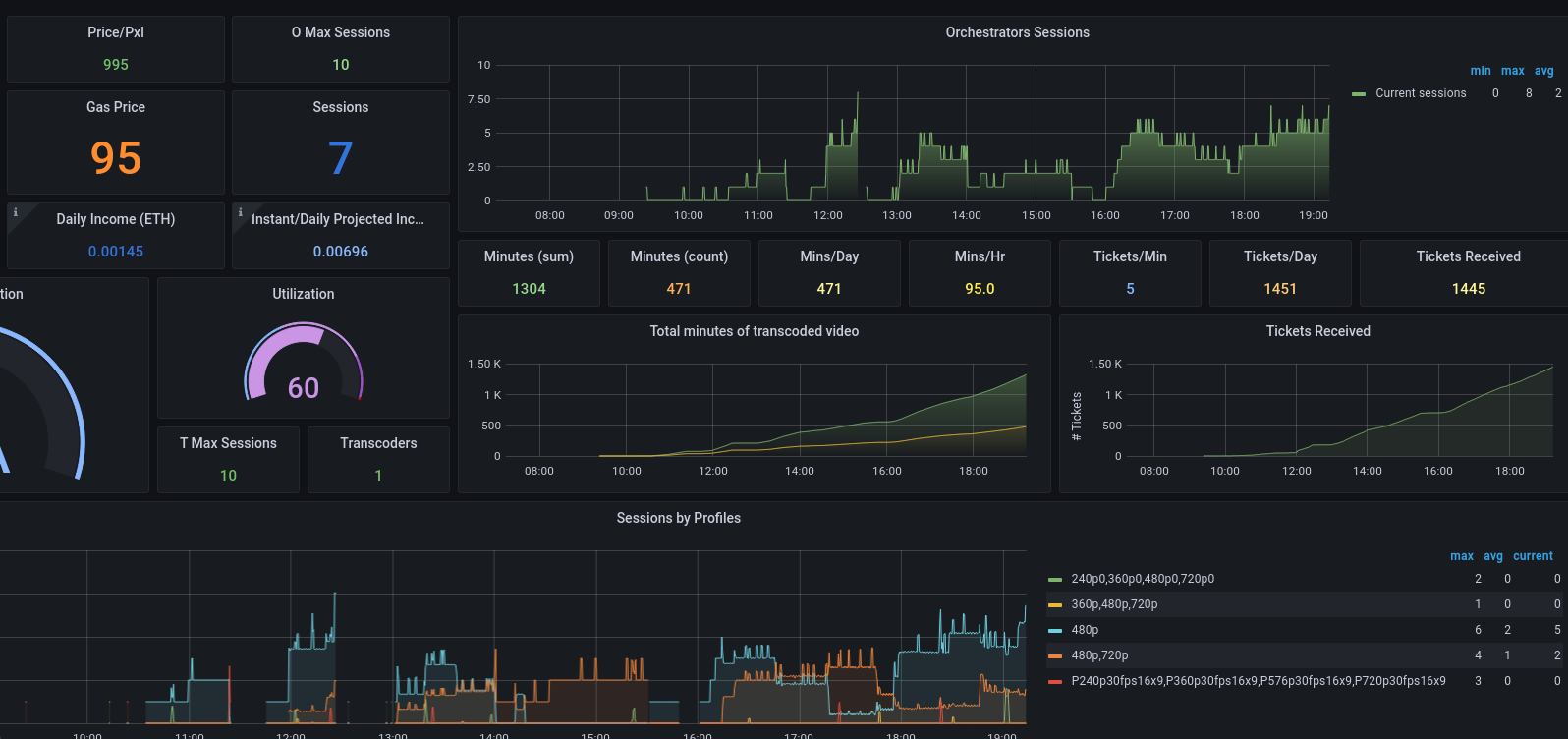
**Networking Challenges and Dashboards**
One of the other things I wanted to setup was dashboards so I could track the performance of both my livepeer setup and my mining performance. My orchestrator is running on `lp.jasonernst.com` on AWS, but my transcoder and ethereum fullnode were running on my home LAN on the main gaming computer. Originally when I started playing around, I exposed the ethereum API port and immediately starting seeing logs for people trying to unlock the wallet / spend funds, so I quickly closed this down. Instead, I have a single machine (the server) configured as an SSH jump box. This means that in order to SSH from outside of my LAN into any computer other than the jump box, must go through the jump box. I then setup an SSH tunnel which made it appear as if the eth full node was running on `localhost:8545` on the orchestrator without needed to expose any ports publicly.
```
# https://gist.github.com/drmalex07/c0f9304deea566842490
- name: Copy Secure Tunnel Service File
become: true
tags: livepeer
copy:
src: files/secure-tunnel@.service
dest: /etc/systemd/system/secure-tunnel@.service
mode: '0600'
# note: for this to work the first time, you'll need to do an ssh first and
# accept the key
- name: Copy Ethereum API Tunnel
become: true
tags: livepeer
copy:
src: files/secure-tunnel@ubuntu-desktop-beast
dest: /etc/default/secure-tunnel@ubuntu-desktop-beast
mode: '0644'
- name: Enable Secure-Tunnel Ethereum
become: true
tags: livepeer
ansible.builtin.systemd:
name: secure-tunnel@ubuntu-desktop-beast
enabled: true
state: started
masked: false
```
https://github.com/compscidr/iac/tree/master/ansible/roles/livepeer/orchestrator/files
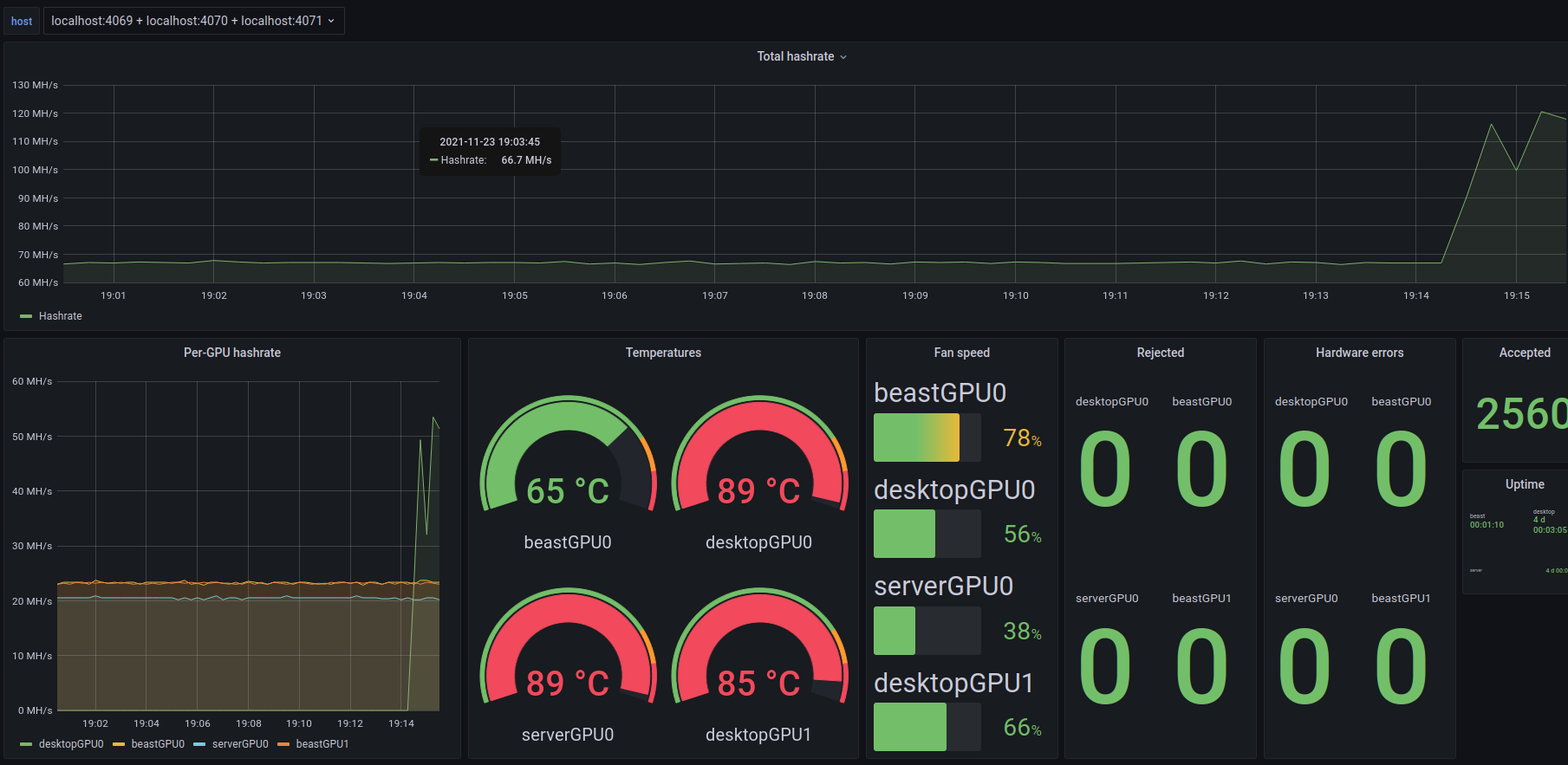
I wanted all of the dashboards to be located in a central location, so I put them on lp.jasonernst.com:3000, but didn't want to expose this publicly, so setup another SSH tunnel from my desktop and then go to localhost:3000 in a browser to see grafana. I also needed the prometheus collectors to reach out to my mining machines to be able to query the hashrates, GPU temperatures, etc, so I setup tunnels to each machine doing mining (the main gaming rig, the backup desktop, and the server).
```
- name: Create Miner Exporter Directories
tags: prometheus
become: true
file:
mode: '755'
path: /etc/lighttpd
state: directory
- name: Copy Miner Exporter Files
tags: prometheus
become: true
copy:
src: files/lighttpd.conf
dest: /etc/lighttpd/lighttpd.conf
mode: '0644'
- name: Create Prometheus Directories
tags: prometheus
become: true
file:
mode: '755'
path: /etc/prometheus
state: directory
# https://forum.livepeer.org/t/guide-transcoder-monitoring-with-prometheus-grafana/1225
- name: Copy Prometheus Config
tags: prometheus
become: true
copy:
src: files/prometheus.yml
dest: /etc/prometheus/prometheus.yml
mode: '0644'
- name: Deploy Prometheus
tags: prometheus
vars:
ansible_python_interpreter: "/usr/bin/env python3-docker"
community.docker.docker_container:
name: prometheus
image: prom/prometheus
pull: true
restart_policy: unless-stopped
network_mode: host
volumes:
- "grafana-storage:/prometheus"
- "/etc/prometheus/:/etc/prometheus"
- name: Deploy Miner Exporter
tags: prometheus
vars:
ansible_python_interpreter: "/usr/bin/env python3-docker"
community.docker.docker_container:
name: mining-exporter
image: compscidr/mining-exporter
pull: true
restart_policy: unless-stopped
network_mode: host
volumes:
- "/etc/lighttpd:/etc/lighttpd"
env:
RIGS: "rig1=( lolminer localhost 4069 ) rig2=( lolminer localhost 4070 ) rig3=( lolminer localhost 4071 )"
```
I've made a docker container out of the `mining-exporter` folder from this repo: https://github.com/compscidr/prometheus-mining and set it to collect lolminer stats from each of the tunnels defined in `RIGS`.
And an excerpt from the `promtheus.yml` file which is set to collect lolminer metrics from `9093` and livepeer metrics from `7935`:
```
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: 'lolminer'
metrics_path: /metrics
static_configs:
- targets: ['localhost:9093']
- job_name: 'livepeer'
metrics_path: /metrics
static_configs:
- targets: ['localhost:7935']
```
The full configuration is available here: [https://github.com/compscidr/iac](https://github.com/compscidr/iac)