Over the last six months or so, a couple friends and I have been working on and off on a hobby project to do indexing of IPFS content: [https://github.com/compscidr/ipfs_indexer](https://github.com/compscidr/ipfs_indexer).
We wanted to use rust in order to learn a bit about it. Currently the way this thing works, is it starts with a seed CID (the hash / address that IPFS content are given. From there, we add the CID to a queue. We then have some number of worker threads depending on how many processors / threads are available on the machine to start working through the queue. These worker threads pop items off the queue, download the content from an IFPS gateway and parse it. The parsing does a few things:
1. It figures out any other IPFS links in the page, and adds these CIDs to the queue.
2. It creates a map of all words and their frequency for the page
3. It updates the global maps of all keywords and adds the CID of the page to the set that the keyword is mapped to
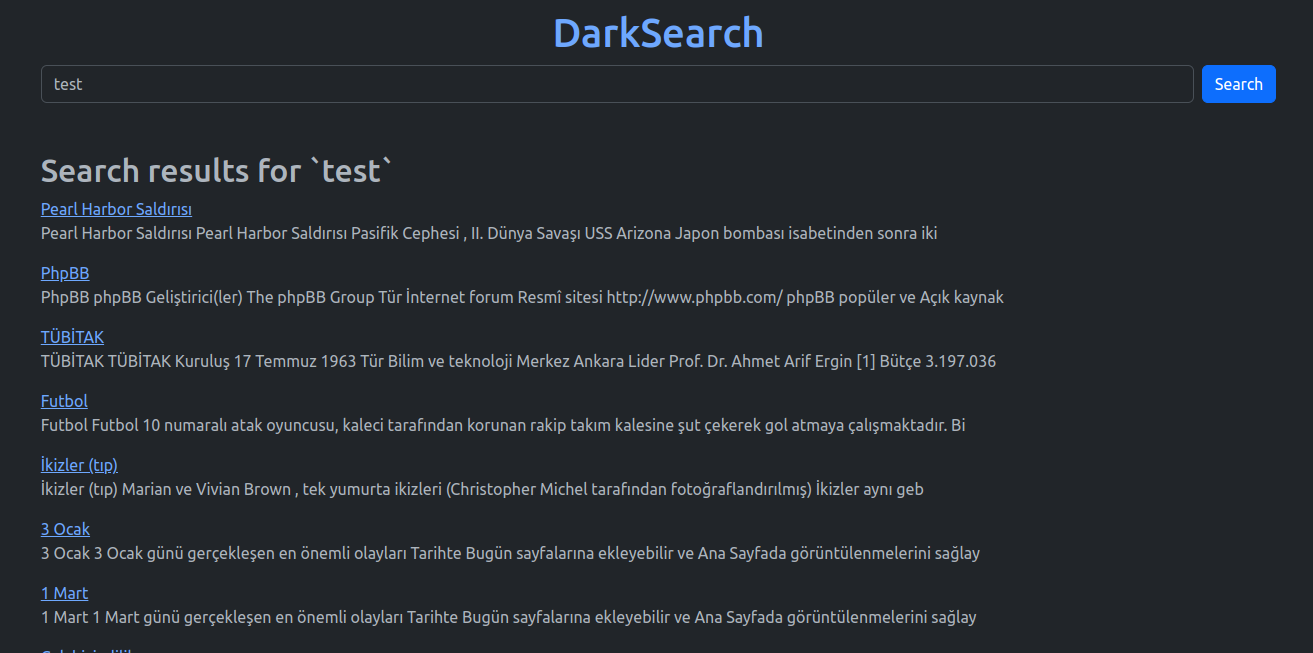
This IPFS indexer also has a few endpoints - one is a query endpoint. When you pass a query, the indexer looks up the words in the map and returns "IndexResults" for the word. The IndexResult contains the page title, keywords, an extract and the CID. This is all the information we really need to show search results.
Today I also hooked up a simple website to the indexer so that people can search the index. You can try it out at [darksearch.xyz](https://darksearch.xyz). At first when I set this up, I set the up the webserver, the indexer and an ipfs gateway up on the same instance of whatever the smallest digital ocean droplet is. It worked, but the indexer quickly ran out of memory and started thrashing the disk. Since then I've moved the indexer to a computer at my house, and its working quite well. Will need to make further updates to move the index into an sql db so that there can be persistence of the index, and so that it doesn't run out of memory.